
AI 算力解决方案
- 丰富的 GPU 型号,如A100/H800/A800/4090/3090等,可满足从 LLM 到 AIGC,从模型微调到推理等各种需求
- 灵活的交付方式,可支撑裸金属服务器、IaaS 云服务器、容器部署等多种方案,同时适配于多种算力的使用方式
- 广泛的区域分布和算力弹性,可覆盖不同地区的算力需求,性价比行业领先
申请试用
方案能力
VALUE

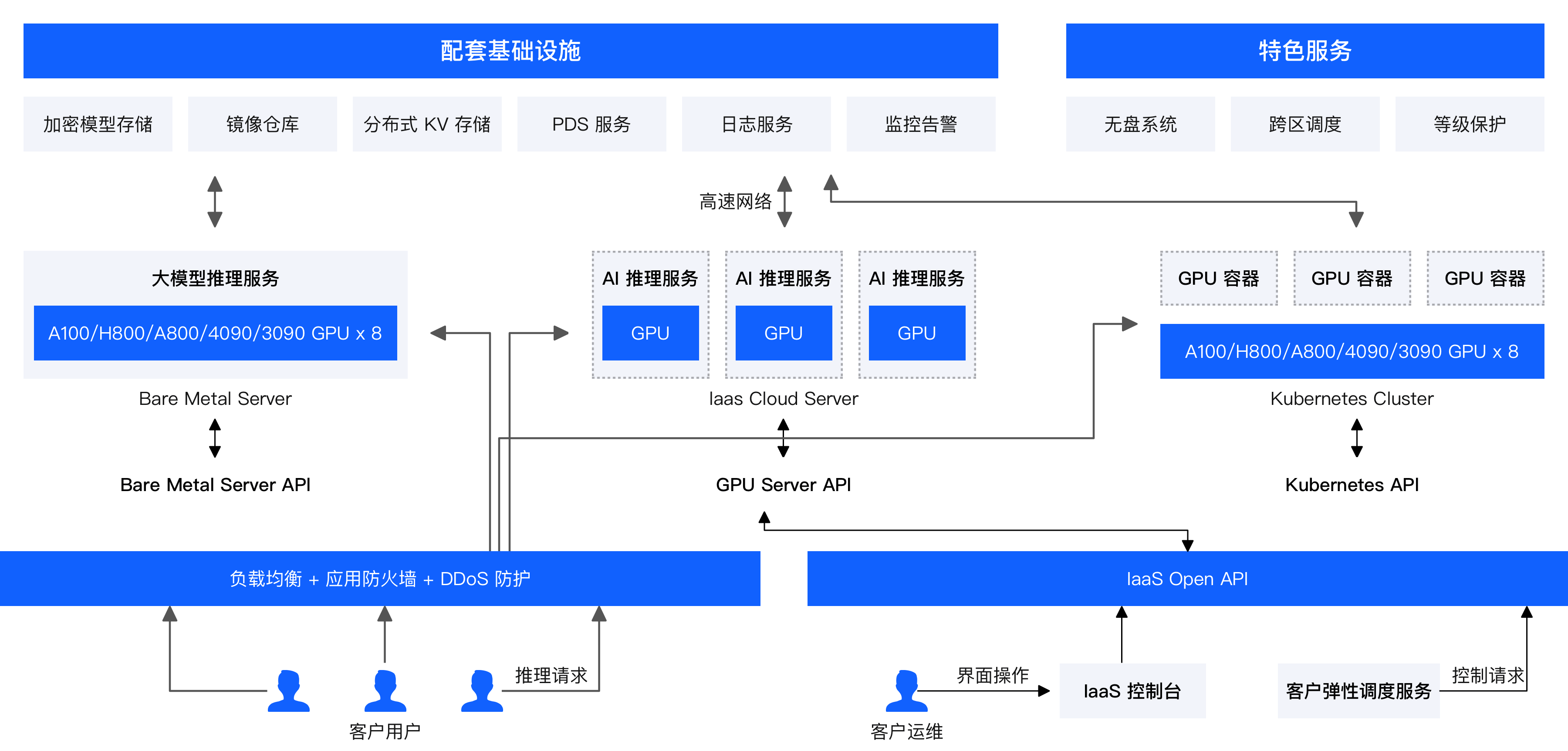
统一调度高效运维
通过 PPIO GPU Cloud的全栈能力,提供裸金属、API 化的 GPU 云服务器、标准 K8S 的容器服务等多种交付能力,可便捷高效地满足客户的使用场景和运维要求;同时提供7*24小时服务监控及保障方案,确保服务高可用

快速可获得
通过 PPIO 广泛分布的算力资源,丰富的 GPU 型号,高效的调度交付能力,即时获取算力资源和快速扩容,按需付费,节约成本

易用高扩展的存储
独有的存算分离无盘系统,使得一个集群中的算力可以共享一份基础存储,以此提供 EB 级别的大模型和数据存储能力,可在 AI 计算场景下提供高效廉价的数据管理和快速升级迭代的能力
方案架构
ARCHITECTURE
适用场景
SCENARIO OR USE CASE
语言模型微调推理
SD 模型训练推理
机器学习和加速计算

语言模型微调推理
对主流的 LLM 模型如 LLAMA、ChatGLM、Baichuan 等开源模型,进行微调训练,推理部署。可广泛应用于聊天机器人、智能客服、社交媒体等场景中,有效解决对话模型中的语义理解和交互问题,提高用户交互的自然性和流畅度

SD 模型训练推理
快速训练和部署 Stable Diffusion 模型,为用户提供快速通过文字生成图片的能力。丰富的资源类型和弹性能力,让业务无需担忧计算能力,专注模型的能力即可。具有高效运维、弹性高可用、按需低成本的优势

机器学习和加速计算
计算机视觉、推荐系统等领域的传统算法,如深度神经网络、图像分类、目标检测等;加速计算领域如进行游戏、动画渲染、科学研究、工业仿真等,均可使用 GPU 进行大幅提效降本



售前专家免费服务
预约定制方案

 沪公网安备 31011502015403号
沪公网安备 31011502015403号